Key takeaways
– We show how clustering analysis of innings progressions can be used to group players with similar batting archetypes, such as low-risk players who increase late innings run-rate beyond the average tempo.
– England’s middle order (positions 3-5) compares favourably against that of Australia, with higher run and control rate predictions.
– In the final 10 overs of ODIs, our algorithm groups England’s Jos Buttler by himself as having an incomparably high scoring rate, but also identifies Australia’s Glenn Maxwell in the next most dangerous group of players.
As World Cup holders Australia prepare to take-on hosts England, we have applied two of OptaPro’s new advanced metrics to highlight differences in the batting approaches between the two sides.
In our previous blog, we introduced modelling player innings progression based on predictions of run-rate and control rate. These methods provide a means of visualising match data on a fine scale, which enables us to extract more detailed information on player performance. The next step in utilising these methods is to use our model outputs to identify similar player archetypes, which can be used for understanding team composition.
Grouping similar batsman types
To briefly recap, the metrics which we defined in the previous blog are:
Predicted Runs per Delivery: We consider runs per delivery rather than strike rate. This is to distinguish between strike rate, which typically considers the total innings scoring rate, and predicted runs per delivery, which is purely a prediction of scoring rate for a particular delivery faced in an innings.
Predicted Controlled Shot Probability: This is the probability that a batsman will be in control of a delivery. We define controlled shots as those in which the outcome of the shot was the desired outcome from the batsman, ranging from a well-timed lofted shot to a well-judged leave outside off stump.
Using these metrics, we can assign players to various groups, based on the similarity of their results. For example, we could group players together with similar runs per delivery progression, or similar control rate progression. It is also possible to combine these metrics to group players who have similar run and control rate evolution. For example, we could use this tool to identify low-risk players who increase late innings run-rate beyond the average tempo.
To do this we use clustering algorithms. The basic idea is that we are grouping curves based on the distance between them across the timeframe of interest. Curves which are typically quite close to one another are likely to be placed in the same group. More details on this algorithm can be found at the end of this blog.
Comparing England and Australia’s engine room
One of the key differences between England and many of the other teams at this year’s World Cup is their consistent aggression throughout the batting line-up, particularly in their ‘engine room’ (positions 3-5).
To explore how England and Australia’s key engine room players construct their innings, we have modelled their runs per delivery and control shot probability along with batsman in the same positions from all the other 2019 World Cup teams.
To identify batsman archetypes, we have then used our clustering algorithm to group players based on both their control and run rates simultaneously. We can observe the unique traits of each group, where we have chosen the number of groups here (six) arbitrarily and this could be increased to gain further descriptive clusters.
The following plots represent the six groups of engine room players and shows their predicted run and control rates, with Australia and England’s players highlighted in gold and blue respectively. The dashed white lines represent the average performance from all players.

Each group in this analysis has a unique trait. Groups five and six are the two most cautious clusters in terms of run accumulation, but with a relatively low and high control rate respectively. Note that none of the Australian or England players appear in this group, highlighting that both team’s engine rooms are consistently proactive.
Groups three and four are somewhat similar, but group three has a consistently higher run rate corresponding to a reduced initial control rate in comparison to group four, although this improves to match group four’s control rate by 50 deliveries faced. Finally, groups one and two are the big hitters.
It’s interesting to note the similarities and differences in how the English and Australian engine rooms tend to operate. Batting at three and four, both Root and Morgan are grouped together with Smith and Khawaja respectively. They operate in very similar fashions, but key to England’s batting success can be observed by their consistently higher run and control rates of each pair. For example, Joe Root’s consistently higher run and control rates corresponds to a batting average of 60.39 runs per dismissal at a strike rate of 91.80 since the 2015 World Cup, compared to Steve Smith’s batting average of 43.36 runs per dismissal at a strike rate of 84.59. Observing their similar approaches grouped together by our algorithm, it is clear they are the glue in each team with steady run accumulation and high control rates, but Root has been slightly more consistent in both areas.
Similarly, we can observe the difference in the big hitters (groups one and two). Here we can see that Maxwell, who is grouped with Hardik Pandya, hits at a consistently high run a ball rate. Buttler takes a little more time to get going, but his acceleration is greater than what Maxwell tends to manage. Furthermore, Buttler’s control rate has a higher prediction throughout the first 50 deliveries compared to Maxwell, whose control probability decreases steadily throughout the innings at no gain in run rate.
Final 10 over player groups
Another example of how we can use clustering to separate player types and understand team strengths can be shown by grouping the batsmen from their final 10 over performance, a metric analysed in our previous blog, where in this instance grouping is solely based on runs per delivery.
This clustering groups players, who have scored at least 400 ODI runs since the 2015 World Cup, who have a similar approach in terms of run accumulation in the final 10 overs of an innings. Highlighted are some key players from England, Australia and also India.
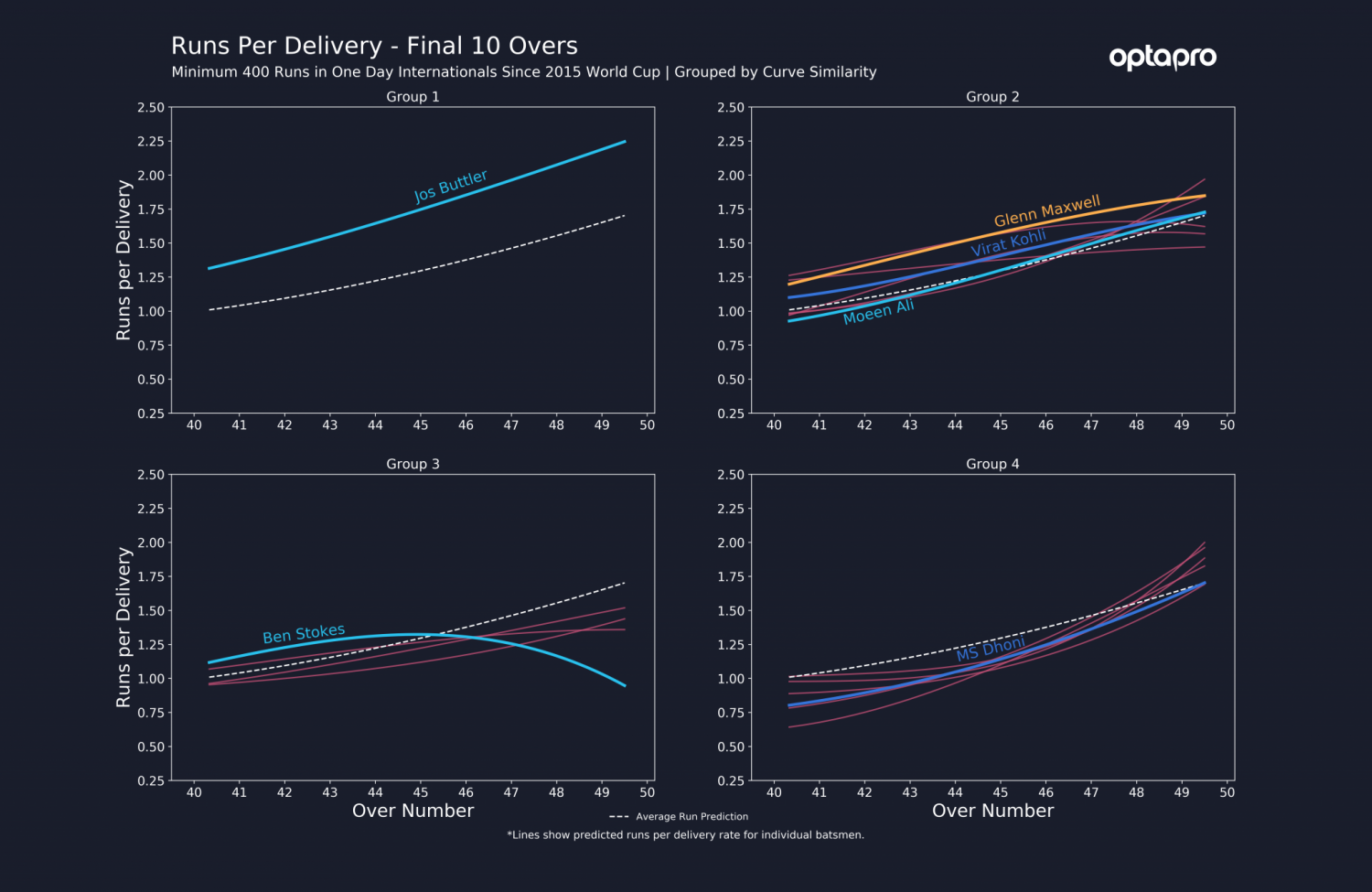
Firstly, let’s observe group three, which contains England’s Ben Stokes. Although the runs per delivery rate starts out high in overs 41-46, this group shows a considerable drop off for the final four overs when compared to the other groups. These players appear to hit a limit on run rate at around 1.00-1.25 runs per delivery in this period of the game. This is still a very quick rate of scoring, but they do not appear to consistently hit that extra gear to elevate their runs per delivery above 1.50. Ben Stokes even shows a dip in runs per ball rate, possibly due to trying to overhit the ball. This could potentially be a weakness for England in the closing overs, but prediction at the very tail end of the innings can be uncertain for players with few data points, of which Stokes is a prime example. This is discussed further at the end of this blog post.
‘The algorithm also groups Buttler by himself. As discussed in the previous blog, his acceleration in the final 10 overs is unparalleled in this set of players. Therefore, the clustering algorithm identifies his curve as unique with no equivalent. However, the remaining two groups show some interesting comparisons between players.
On the one hand, groups two and four follow a somewhat similar pattern of acceleration throughout the final 10 overs. In fact, a brief glimpse might not reveal any major differences between them, since both groups have similar runs per delivery predictions at 50 overs of around 1.25-2.00. However, the key difference between these groups is the build-up in scoring rate.
Group two, which includes England’s Moeen Ali, India’s Virat Kohli and Australia’s Glenn Maxwell, are already scoring above the average run prediction by the 45th over. They tend to accelerate early but steadily throughout the final 10 overs. However, players such as India’s MS Dhoni in group four, tend to delay this acceleration. Hence, although group four players tend to increase to a very respectable run rate towards the 50th over, they accelerate deeper into the innings than those in group two.
Conclusions
The two examples in this blog show various ways in which grouping players based on their run and control rates can be used to understand team and player strengths.
By grouping the engine room players at this World Cup by their individual innings composition, it is clear to see why England have consistently scored at a rate unmatched by any other team. When compared to their Australian counterparts, England’s middle order performs favourably both in terms of run rate and control rate.
In addition, we can also see why England have been so strong during the final 10 overs of an innings, with their batting order containing highly destructive late order players who tend to accelerate earlier than most in this period of the innings.
These examples are just scratching the surface of how run and control rate modelling, along with clustering algorithms, can identify player archetypes. We have observed specific categories of international players in ODIs, but there is a wealth of various other international and domestic competitions which our models and methods will be applicable to.
*Further Model Details:
To group similar curves, we use Euclidean distance complete-linkage Hierarchical clustering. The features we cluster on are the predicted GAM values at each delivery, so over a 50 delivery segment, each player will have 50 features. This can be reduced by looking at a subset of deliveries to compare curves on. Although we do not normalise the features when clustering on a single measure, when we cluster players based on both their run rate and control rate, normalisation across measurements is required.
In terms of uncertainty, we can also estimate corresponding confidence intervals of our run and control rates, to give an idea of the uncertainty surrounding our prediction of the mean runs per delivery. These are only a rough guide as a major assumption required for robust interval estimation using our approach does not hold (Gaussian response variables) but it does give an idea of where we have less certainty in our results. We could also consider prediction intervals, but due to the large variability in runs obtainable through a single shot, these intervals tend to be wide and uninformative. Below we show the 95% confidence interval for Ben Stokes, to show how his decreased runs per delivery estimate is during a section of greater uncertainty in our model output, hence this may well be an artefact of lack of data in this period of the innings from Stokes.
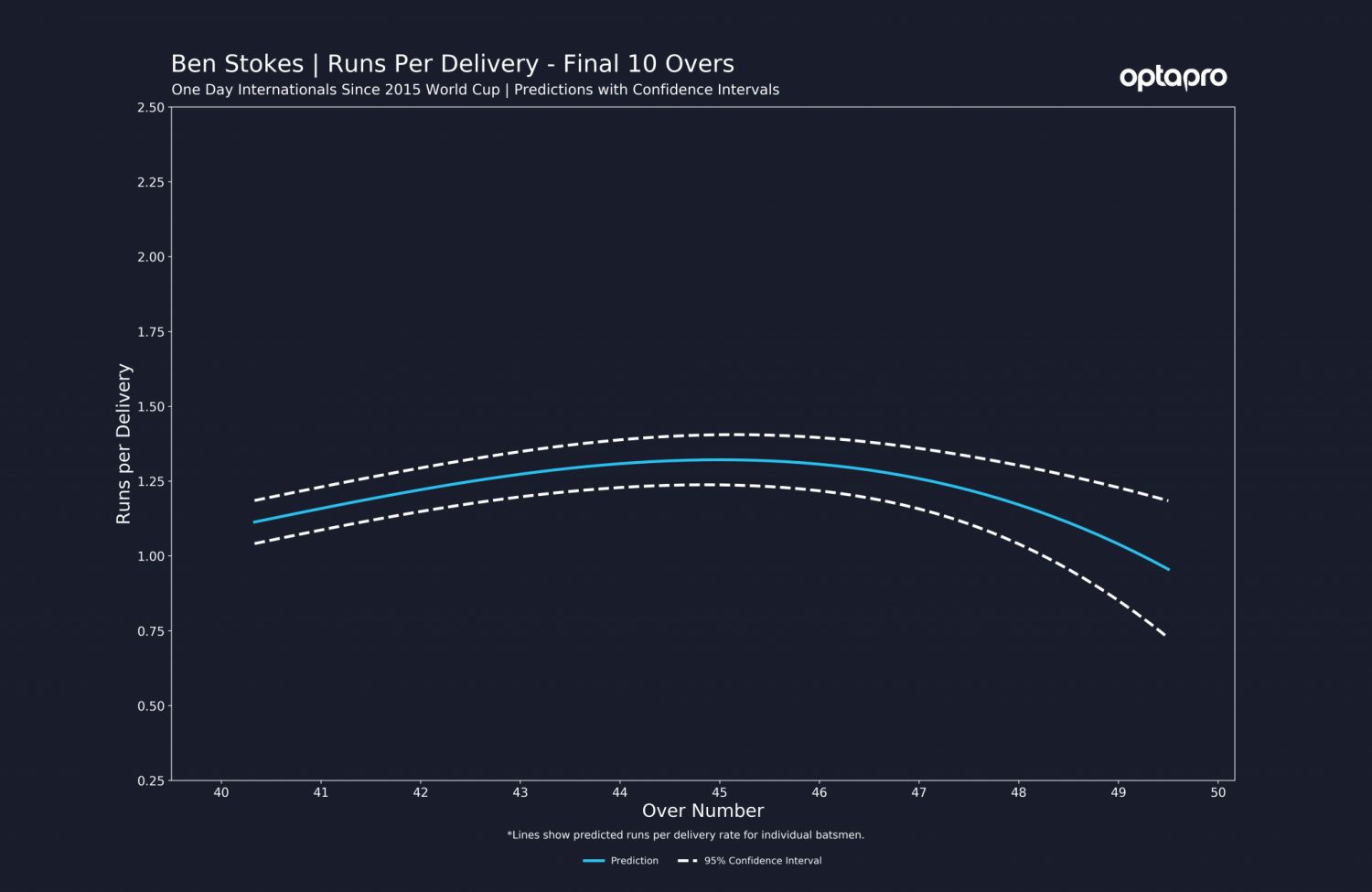
It is important to note that these confidence intervals are most likely to increase at the extreme ends of an innings, where batters have less opportunity to face deliveries. This is why we chose a cut-off of 400 runs in this period of the innings for our plots. This cut-off could be reduced but would require care on spline count and smoothness parameter values used in the model fitting. The output uncertainty is less of an issue in the England vs Australia middle order plots, as we are looking at periods of an individual players’ innings rather than section of a team’s innings.